Räumliche Clusterdetektion mit der Statistik-Software R am Beispiel eines Datensatzes eines Syndromic Surveillance Systems des indischen Bundesstaates Andhra Pradesh
Die Untersuchung der räumlichen Verteilung von Krankheiten gehört zum Arbeitsbereich der räumlichen Epidemiologie. Die Identifizierung von ungewöhnlichen Krankheitshäufungen, sogenannten Clustern, mithilfe von statistischen Methoden kann einen wertvollen Beitrag zur Bestimmung potentieller Risikofaktoren bei der ätiologischen Forschung leisten.
Einige dieser Verfahren zur räumlichen Clusterdetektion von Krankheiten sind im DCluster-Package für die frei verfügbare Statistik-Software R implementiert. Basierend auf einem Datensatz eines Syndromic Surveillance Systems, das derzeit im indischen Bundesstaat Andhra Pradesh aufgebaut und getestet wird, wird in R eine Clusterdetektion mithilfe der Spatial-Scan-Statistic-Methode nach Kulldorff durchgeführt.
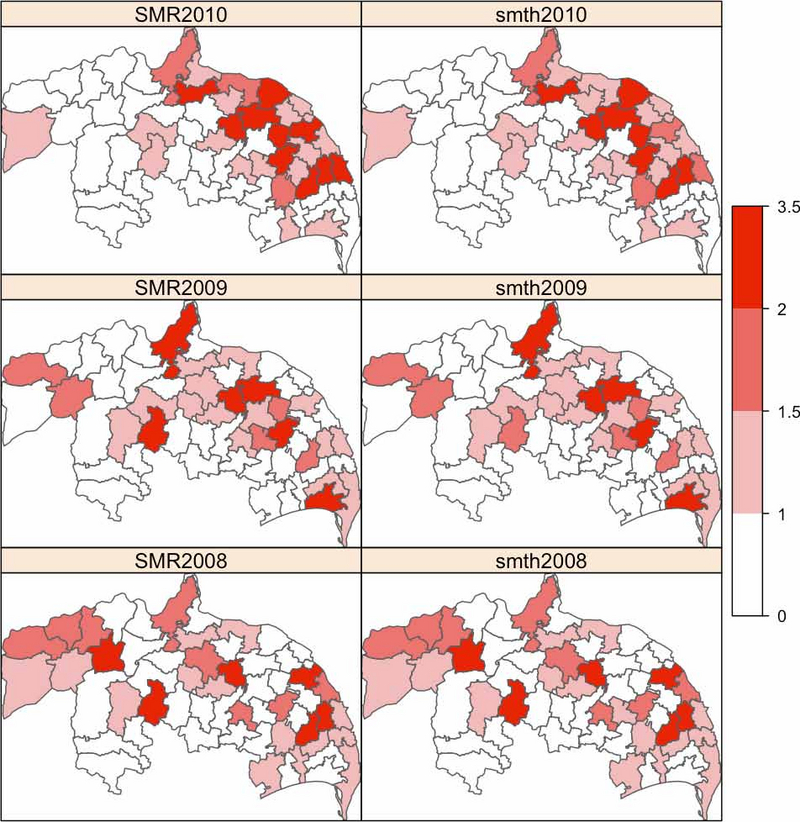
Dabei werden Regionaldaten verwendet, die die Gesamtzahl der Krankheitsfälle in einer bestimmten Region und einem bestimmten Zeitraum beschreiben. Die Ergebnisse werden kartographisch dargestellt und mit den Resultaten, die sich aus dem Disease-Mapping ergeben, verglichen. Zum Disease-Mapping gehören die kartographische Darstellung der relativen Erkrankungsrisiken und die dazugehörigen Probability-Maps.
Es zeigt sich, dass die Wahl des zugrundeliegenden statistischen Verteilungsmodells sowie der Scanparameter einen entscheidenden Einfluss auf die Clusterfindung hat und teilweise zu inkonsistenten Ergebnissen führt. Dennoch konnten in den drei untersuchten Distrikten Regionen mit signifikant erhöhtem Erkrankungsrisiko gefunden werden.